
Overview
起因
近几个月的吃饭时间在刷 IMDb Top 250 的电影, 一般的操作流程是先去搜索电影名字,然后找到豆瓣电影的链接,最后再去找国内的正版播放源。 这一过程很繁琐,身为程序员的我肯定忍不了, 于是便开始自己动手编写 Tampermonkey,也称作“油猴”。
过程
- 从IMDb页面跳转到豆瓣页面
我们都知道,从豆瓣电影页面是可以直接跳转到IMDb的,但是反过来却不行。 在网上搜索了一番,没有结果。 最后偶然的一次尝试,在豆瓣电影的搜索栏里输入了某部电影的IMDb编号时,下拉框出现的目标的电影信息, 打开 Chrome 的开发者工具,找到了那个请求,如图: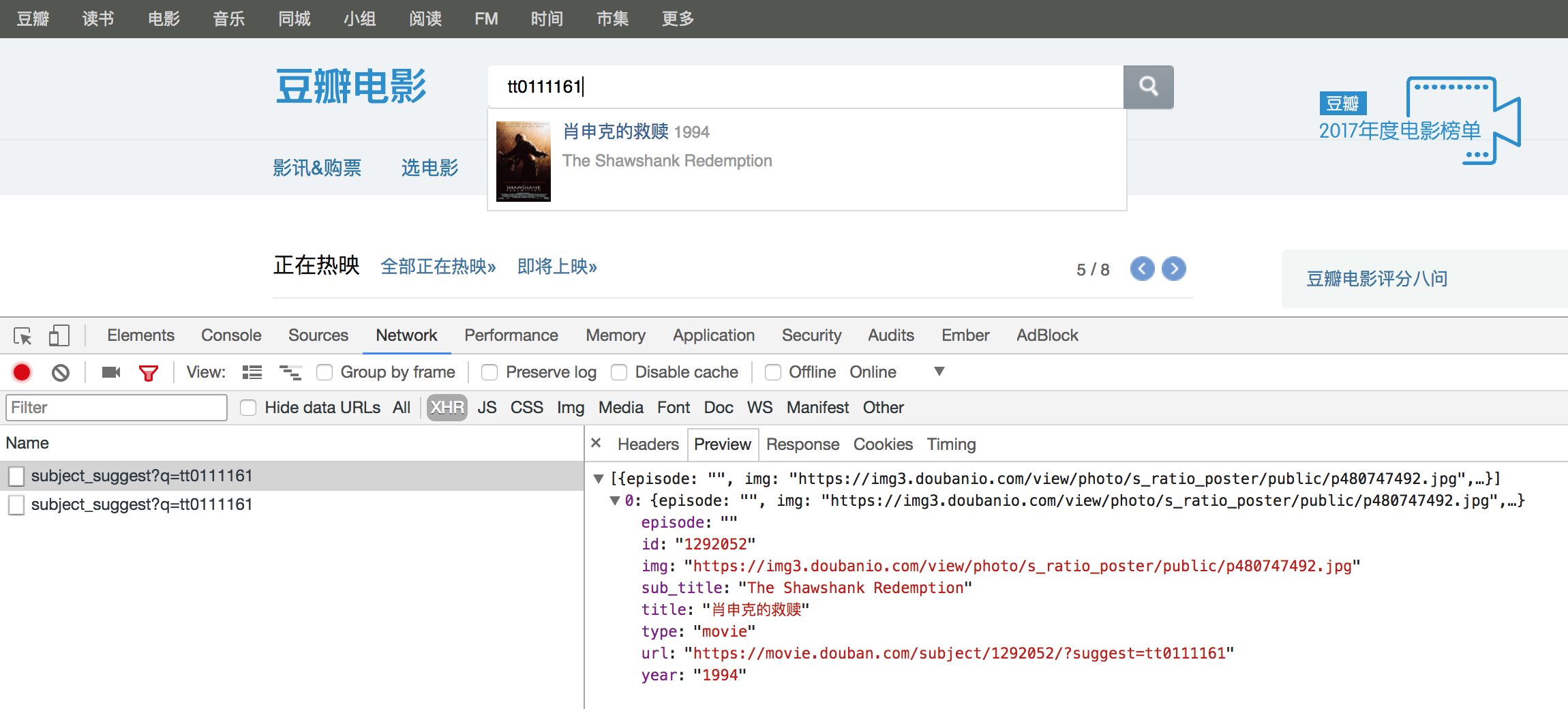 但当我用
但当我用$.ajax()请求那个地址的时候,却提示No 'Access-Control-Allow-Origin' header is present on the requested resource., 再次搜索一番,找到了解决办法 GM_xmlhttpRequest。 - 找到国内的播放源
最初尝试用百度视频的搜索结果,但发现有两个问题,一是链接有的不准确,二是搜索结果有时乱(因为通过电影标题搜索)。 正纠结着如何解决,又一个偶然的发现,原来豆瓣电影页面也有播放源的数据! 查看了一下数据来源,原来是页面里的,继续用 GM_xmlhttpRequest 来获取。
最终效果如下:
查看了一下数据来源,原来是页面里的,继续用 GM_xmlhttpRequest 来获取。
最终效果如下:
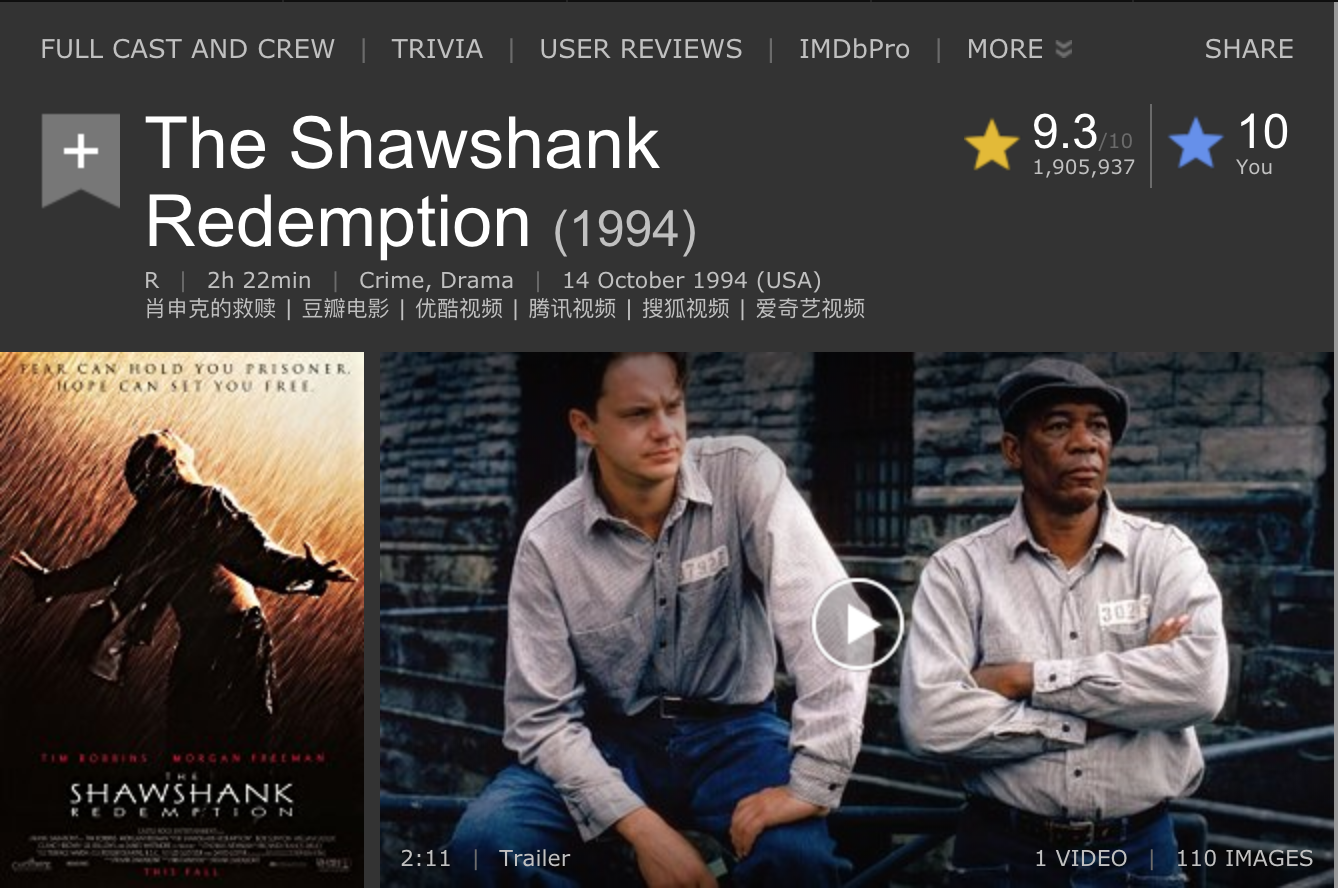
附上代码
代码量非常少,具体见下:(ps:我是个js渣渣。)